
The Motivator
5 Simple Machine Learning Algorithms To Train Neural Networks

What are Neural Networks?
Neural networks are a series of algorithms that emulate different operations, how a human brain recognizes various relationships between large volumes of data. From forecasting to marketing research, fraud detection, and managing risks, neural networks play a crucial role everywhere.
A neural network is a mathematical function that helps in collecting and classifying information based on specific layouts. It is very similar to statistical methods like curve fitting and regression analysis. A neural network contains various layers of interconnected nodes that are similar to multiple linear regression models. The input layers gather input patterns. For example – if you consider it as an e-commerce business. Then sell, buy, abandonment is a few input patterns.
How is it Helping Data Science?

A neural network is an advanced machine learning technique where you train the systems with individual cases and update the training algorithms based on errors. So, when it gets tested for the next time, it produces fewer errors. The weights update happens in two ways: feed-forward techniques and backpropagation techniques.
Feedforward involves processing all the observations one at a time. It uses training data and trained data to predict the outcomes with the actual outcomes. And calculate the errors in your model for that particular observation. On the other side, the backpropagation method involves taking the errors back through the networks; it adjusts individual weights for better results.
When to Use Neural Networks?

For all the critical problems related to data science, Neural Networks are one family for many approaches to solve business problems instantly. This technique can be sturdy many times in solving problems related to human brains such as text, image, or voice recognition.
5 Algorithms that keeps Neural Networks on Trending
Algorithms are programming code; they simplify our work and analyze the larger data volume in a lesser time. And if you understand Python or R, it’s easy to code and spot the errors and execute in the least time with higher accuracy. Here are the best five of the algorithms that always keep neural networks on trending. Let’s explore them one after another in more detail.
Gradient Descent
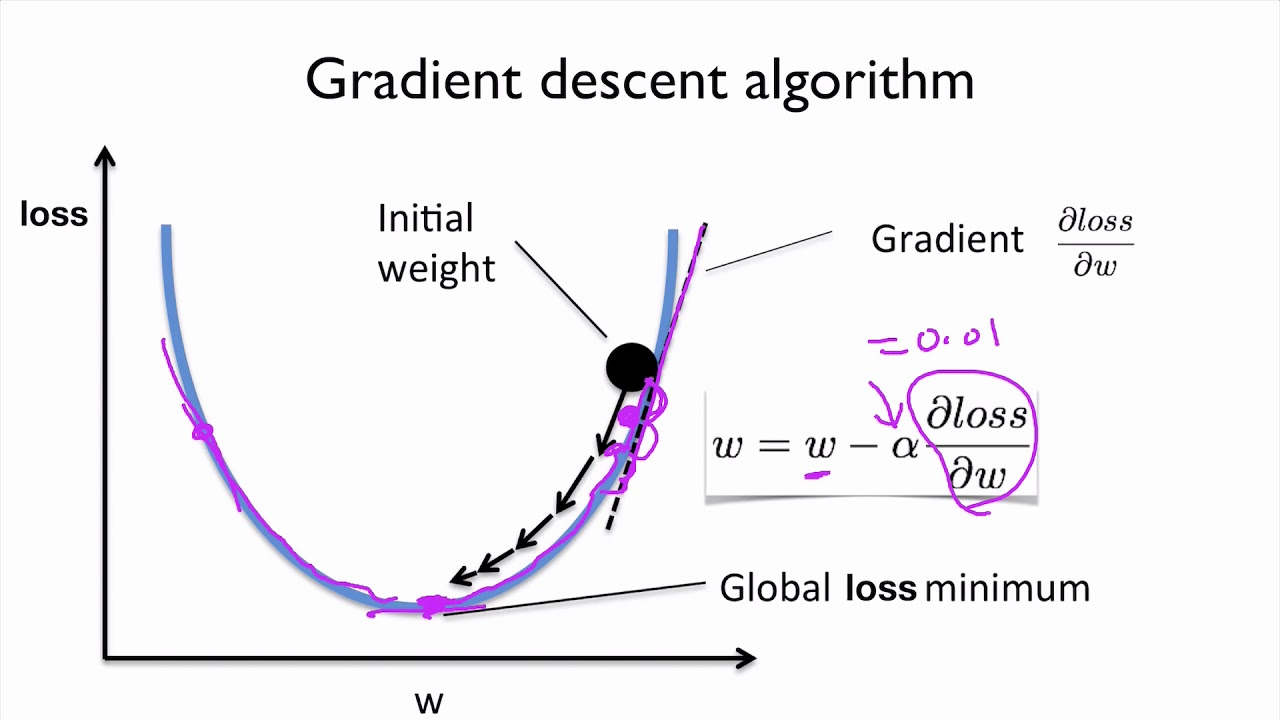
Gradient descent is an advanced machine learning optimization algorithm. It works based on convex function and some tweaks in the parameters recursively to minimize local minima to the maximum.
For the gradient descent method, you can insert the initial value. And this method will apply the calculus method iteratively to minimize the given cost function to the least as possible. The equation below describes the next position we need to check. That is the direction of the steepest descent
Newton Method
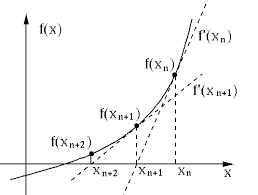
Newton’s methods for CNN involve complicated operations, and thorough research is highly essential for success as the newton methods give competitive test accuracy among all the algorithms. Newton’s method is the 2nd order equation as it makes the uses of the Hessian matrix. The main objective here is to use a second-order derivative of the loss function to find better training directions.
Conjugate Gradient

The conjugate gradient method is one of the most effective strategies for training neural networks as it requires a low memory and gives higher convergence. It accelerates the typical slow convergence processes associated with gradient descent. This method solves the complex problem with ease with the evaluation storage and uses the inverse Hessian Matrix.
Here the search performs along with conjugate directions for faster results, and this training gets conjugated concerning the Hessian matrix. And the results we get are quicker than the gradient descent directions.
Quasi-Newton Method

It’s a backpropagation algorithm method to train self-learning neural networks for better and faster results. The convergence rate is sluggish here as it’s a backward propagation method with the steepest descent slope. With some modification, the problem size is not proportional to the number of weights but the number of neurons at each step. The results show that the Quasi-Newton method solves faster without there is a need for increasing the storage space.
Levenberg-Marquardt Algorithms

The Levenberg-Marquardt algorithm, the other name as a damped least square method works best for the loss functions. It sums of squared errors. It works with gradient descent and the jacobian matrix without the exact Hessian matrix.
Final Thoughts
Storage is a prime concern in data science and has numerous parameters, and uses gradient descent or conjugate gradient, to save in the memory. In the list of all the five algorithms, the Levenberg-Marquardt algorithms are the best and widely used. And for the rest of the situations, Quasi-Newton methods work very well.
Reference link – https://www.excelr.com/blog/data-science/regression/understanding-logistic-regression-using-r


1 Comment