The Motivator
Google Translatotron translates and imitates user’s own voice
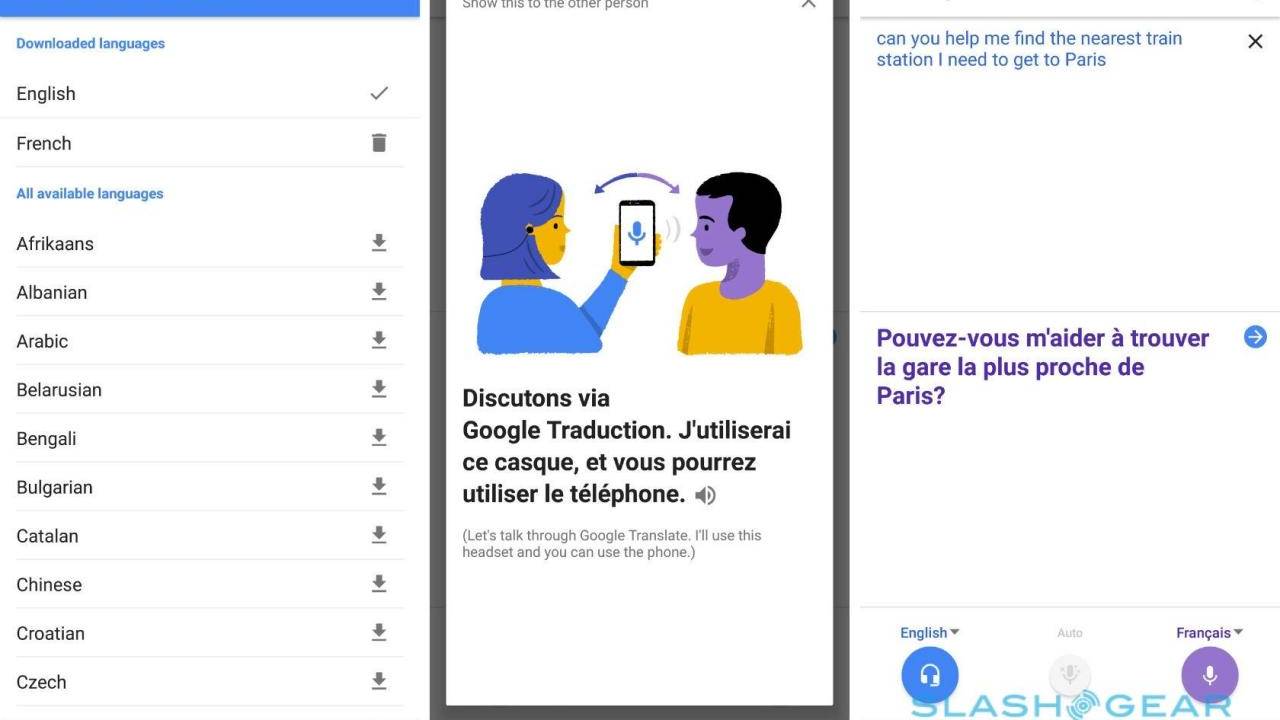
We might be on the verge of reaching uncanny valley when it comes to real-time translation of the spoken word. It’s already amazing how systems, particularly Google’s, are now able to translate what we say on the fly but almost all of those speak in their own obviously synthesized voices. What would you feel if you heard yourself speaking another language you barely know? That’s the magical and almost unsettling future that Google Translate might offer thanks to Translatotron.
Translatotron isn’t a new Transformers character. It’s just the nickname that the AI researchers at Google gave their End-to-End, Speech-to-Speech Translation Model. EESSTM (Esteem?) just doesn’t sound as catchy nor as tongue twisty.
Translatotron’s ability to retain the source speaker’s voice even in the translated speech is actually just an effect of the system’s true nature. Most translation systems split the job into three parts. One turns speech into text, another takes that text and translates it into another language, while the third turns the text back to speech, often in a different voice from the original speaker.
This cascaded system has proven to be efficient and practical and is what drives most translation systems, including Google’s. Google’s AI researchers, however, believe that an end-to-end system can actually outperform it by removing the middle man. Literally, it skips the part where speech is translated into text first.
Translatotron didn’t yet outpace the traditional cascaded systems in the team’s tests but it proved that it was at least feasible. Like any machine learning model, it could improve over time. Given the advantage of preserving the speaker’s original voice even in the translated speech, further research in this field could prove to be fruitful for Google’s future AI-powered translation systems.
Source: https://www.slashgear.com/google-translatotron-translates-and-imitates-users-own-voice-16576889/